
3 Model Evaluation
模型评估
经验误差与拟合问题
在分类问题中,将分类错误的样本占样本总数的比例称为错误率。如果在$m$个样本中有$a$个样本分类错误,则错误率为$E=frac{a}{m}$,与之相对的精度为$Accu=1-E$。或者,我们将学习算法的实际预测输出与样本的真实输出之间的差异称为误差。学习算法在训练集上的误差称为训练误差或经验误差,在新样本上的误差称为泛化误差。学习算法的训练过程就是努力使得经验误差最小化。但是,我们希望获得的是泛化误差小的学习算法。在一些情况下,我们能得到一个训练集上表现很好的学习算法,但是这种学习算法不一定好,甚至是糟糕的。因为这样的学习算法把训练样本学习得太好了,把训练样本的一些特点当成了样本的一般性质,这种学习算法泛化能力低下。这种现象被称为过拟合。与过拟合相对的是欠拟合。出现欠拟合意味着学习算法学习能力不足,没有发现样本的一般性质。欠拟合的解决方法很简单,只要加强学习算法的学习能力即可。但是,过拟合则十分困难,所以过拟合是机器学习中的重要问题。只要相信$P neq NP$,过拟合就是无法避免的,我们能做的就是减少过拟合所带来的影响。下图是过拟合和欠拟合的类比图 :
评估方法
我们使用实验测试来对学习算法的泛化误差进行评估来做出选择,所以需要一个测试集来测试学习算法的泛化能力。以测试集上的测试误差作为泛化误差的近似。测试集需要与训练集互斥,这样才能较准确地评估学习算法对于没有见过的新样本的泛化能力。对于数据集,既需要训练又需要测试,如何将数据集划分出训练集和测试集是一个问题。下面介绍一些常用的方法 :
- 留出法 : 直接将数据集划分为两个互斥的集合,其中一个作为训练集,另一个为测试集。在进行划分时,需要注意保持数据分布的一致性,避免划分过程中引入额外的偏差对最终的结果产生影响。保证训练集与测试集中各类别的比例相似。同时,可以将数据集进行随机排序,将不同的样本划入训练集,模型评估的结果也会不同。所以单次留出法得到的结果并不可靠,可以多次实验后取均值作为评估结果。此外,我们希望评估的结果是用数据训练出模型的性能。所以,当训练集包含大多数样本时,训练出的模型更加接近用数据集训练出的模型,但是测试集较小,评估结果可能不够稳定准确。若减少训练集样本,则训练出的样本与数据集训练出的模型可能又较大差别。这个问题没有完美的解决方法。我们一般将$frac{2}{3}$~$frac{4}{5}$的样本用于训练,剩下的样本用作测试。
- 交叉验证法 : 将数据集划分为$k$个大小相似的互斥子集,每次使用$k-1$个子集作为测试集,剩下的子集为测试集,进行$k$次训练和测试,取$k$个测试结果的均值作为学习算法的性能评估。若$k$等于样本数目,一个子集只有一个样本,这种方法又叫留一法。留一法实际评估的模型与期望评估的用数据集训练出的模型相似,所以评估结果被认为较精确。但是当数据集较大的时候就会造成难以接受的计算开销。
- 自助法 : 从数据集中随机跳出一个样本,放入训练集,再将该样本放回数据集,使得下次采样依然有可能被采到。一个样本数为$m$的数据集在重复执行这个过程$m$次后,会有一个样本数也为$m$的训练集。有一部分样本会在训练集中重复出现,有一部分不会出现。不会出现的概率为$(1-frac{1}{m})^{m}$。在取极限后有36.8%的样本未出现在训练集,这些样本会作为测试集来使用。这样实际评估模型和期望评估模型都使用$m$个训练样本。还有一些没在训练集出现过的样本用于测试,这样的测试结果,被称为包外估计。这种方法在数据集较小的时候比较有用,但是改变了初始数据集的分布,引入了估计偏差。所以在数据量充足时,留出法和交叉验证法更为合适。
性能度量
对学习算法的泛化性能进行评估,不仅好的评估方法,还需要有衡量模型泛化能力的标准,这就是性能度量。性能度量反应了任务需求,所以在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。也就是模型的好坏是相对的。什么样的模型是好的,不仅取决于算法和数据,还取决于任务需求。接下来的小节,我们来探讨对不同任务的性能度量。
分类任务的性能度量
错误率和精度是分类任务中最常用的性能度量。错误率是分类错误的样本数占样本总数的比例。对于样例集$D$,分类错误率的定义为 :
精度定义为 :
但是错误率和精度并不能满足所有的任务需求。比如在信息检索任务里,我们会关心“检索出的信息中有多大比例是用户所感兴趣的”,“用户感兴趣的信息有多少被检索出来了”。单纯使用错误率和精度来作为性能度量是远远不够的。
上面的需求可以使用查准率和查全率来作为性能度量来实现。以二分类问题为例,可以将样例根据其真实类别与学习算法预测的组合划分为真正例 (true positive, TP),假反例 (false negative, FN),真反例 (true negative, TN),假正例 (false positive, FP)。它们的定义如下 :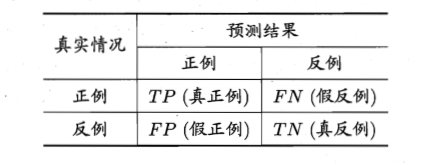
有了上面的定义,查准率$P$和查全率$R$的定义为 :
查准率和查全率是一对矛盾的度量。查准率高的时候,查全率往往偏低。查准率低的时候,查全率往往偏低。使用一个例子来说明,当我们将好瓜尽可能选出,需要放低选的标准,让大多数瓜选上,则查准率降低。如果让选出的瓜好瓜的比例尽可能高,就需要挑选最有把握的瓜,则查全率降低。
学习算法为样本产生一个概率预测,并将这个预测值与一个分类阈值进行比较,大于这个阈值被划为正类,反之划分为反类。

